About This Particular Outliner
Outline Exchange and XML, Part 1: History
This month we depart from our usual survey format and dive into something actually useful. Many ATPO readers simply cannot find the outliner tool that does all the things they wish, so they combine tools. Often, this is facilitated by a standard called OPML, the Outline Processing Markup Language. OPML was created by Dave Winer of Frontier to exchange simple outlines, the kind Frontier creates.
Many outliners on our ATPO tracker list support OPML.
The following both import and export OPML: Circus Ponies NoteBook, Frontier, Hog Bay Notebook, hnb, iTask, NoteTaker, NovaMind, OmniOutliner and OmniOutliner Pro, Process, Pyramid, SuperNotecard, Tao, and Tinderbox (using TinderToolBox).
JOE, MyMind, and iLiner export OPML.
That’s a lot of support, and it works well for outline headers. You can swap files back and forth between OmniOutliner and NovaMind via OPML for instance. OPML is one of those standards that has wide adoption because it is extremely simple, but OMPL also has some serious limits for application integration.
It only exchanges the data associated with the most extreme reduction of what constitutes an outline, because that’s all its creator cared about at the time. So parents, children, and notes (but notes in a less perfect way) are copied, basic outline stuff. Some other information is included that isn’t of interest to any ATPO outliner except Frontier. But between the pair of OmniOutliner and NovaMind for instance, OmniOutliner’s columns and styles wouldn’t convey to NovaMind and coming back the other way, NovaMind’s links are lost. That’s a lot to lose, dear friends.
Another problem is that OPML was created by one fellow. He has refused to turn it over to any group, and for the past four years he has been doing other things and decided not to update it. Many in the business have trouble working with his personality and are frustrated by the absence of evolution.
There are a couple solutions to this problem. One is for the outliner community to take charge of our own standards and create something better than OPML, more capable and flexible, attuned to real needs of outliner integration rather than Frontier tricks—something open and with a real governing board. I’d be willing to help with this. It is outside the scope of ATPM, but I’m sure we can find a forum and a critical mass.
Another solution is what this column series could be about (if there is interest): use XML translations directly. OPML is a format that uses XML. In the past five years or so, the support for XML has ballooned. OS X uses it extensively; all those preference and property list files (.plist) are in XML. A great many of the applications you’d want to export to support XML, including publishing to the Web using the XML form of HTML, XHTML. Before long, every new writing and publishing application—print, Web, and screen—will be based on XML.
Some applications of interest that support XML are: InDesign, Publicon and its sister Mathematica Notebook, FrameMaker (though it is abandoned on the Mac), Word (sorta), FileMaker, and iWork (both Pages and Keynote). Naturally, Dreamweaver and GoLive can accept XML.
On the outliner side, Circus Ponies NoteBook, jEdit, NoteTaker, OmniOutliner, Slacker, Tinderbox, and VooDooPad all expose their own versions of XML which express all the good information and relationships they generate. I’m sure that in short order all the power outliners will, as soon as ATPO readers ask for and begin using it. Tinderbox and hnb actually use XML as their native file format.
So if you are interested in integrating your outliner into your workflow, you’ll likely be using XML unless you convince the developers to create an XML shortcut that’s invisible to you (like OmniOutliner’s relationship with Keynote, Process with OmniOutliner, or Merlin with OmniOutliner and NovaMind).
Direct use of XML for exchange is what we’ll be introducing in this series of columns. The problem of course is that XML is in the category of messy black art. ATPO hopes to alleviate that in some small measure.
XML History
In the late 1960s, largely as a result of the Multics time-sharing research program, IBM had a research lab in Cambridge, Massachusetts, near MIT. That lab was engaged in lots of what became important work: some of the origins of modern operating systems, the database, and many languages have a historical thread that goes through MIT and this lab. In 1968, a problem assigned to the lab was how to mix “programming instructions” with document text to allow legal documents to automatically be indexed, and composed (typeset). IBM had lots of experience in this field; indeed, their “business machines” included compositors before they developed computers.
I visited this lab as a computer science student in 1967 and 1968, where they were developing something that the next year would be tagged “Generalized Markup Language.” The original developers claim that the name was derived from the initials of their last names (which are G, M, and L, at least during a key period), but I seem to recall the name predating the formation of that group. The idea was to intersperse notes among the text as elements of computer instructions that would be “compiled” for layout and publishing.
You have to recall that this was in the center of the Lisp universe in its heady days. Lisp was arguably the most used for research and certainly the most advanced language of the time. (Many still claim so.) Lisp is built on the notion that data and programming instruction are comingled; no, that’s not quite true: in Lisp they are actually the same.
GML appeared in the midst of similar ideas that were popping all over the place, most notably in the Graphic Communications Association (GCA) Composition Committee. But instead of using the strong notion from Lisp where the “tags” were similar in form to the text, they used a weaker notion where the text was one kind of thing and the “tags” were more computer-like,
IBM in those days was both savvy and agile, and in a very short time IBM expanded GML to a product line (“Document Composition Facility” also sometimes “Framework”) for many publishing purposes. At this point, another family tree thread diverged that led to GML-derived codes that formed the basis of Wang Laboratories and the development of so-called “word processors.” But that’s another story.
Independently, but with the backing of IBM, news syndicators (such as Reuters, Associated Press, and the like) invested heavily in a markup language using GML to transmit structured stories. They drove an international standard that resulted in the Standard Generalized Markup Language (SGML), ISO 8879 in 1979. SGML by that time (and since) was seen as a robust means for structuring documents in such a way that content and presentation could be managed separately. It was pretty much the only game in town for the heavy-duty document crowd.
Meanwhile, over the next decades, various much lighter weight proprietary tagging schemes popped up all over the place as the basis for numerous word processing and desktop publishing products. Over time, the complex and costly SGML became more and more marginalized for high end users.
Then two things happened that saved SGML.
The first was a project in the US Department of Defense (DoD) that was dealing with a financial disaster. They bought complex systems in huge amounts, more than any other enterprise in the world. All of these needed manufacturing, training, and repair documents that were typically included in the system procurement. However, as the systems evolved, the paperwork lagged, often by years. And we’re talking a lot of paper here: the typical submarine for example had associated paper that weighed more and cost more (overall) than the sub itself.
Many, many billions of dollars were being wasted by out of date paper, perhaps tens of billions a year, so the idea was to digitize the documents. The very ambitious project to do this was called Computer Aided Logistics Support (CALS). I was at the Advanced Research Projects Agency (ARPA) at the time advising CALS. I lobbied against adopting SGML as a CALS standard (holding out instead for something simpler and more consistent as I’ll explain later, but with process state), but in 1987 SGML became a defense requirement under CALS. Billions of dollars poured into SGML compliance (which continues today). Naturally, this put new life into the tool base. The defense and intelligence world also sponsored lots of research—real research—to extend SGML to support complex structured documents, particularly hypertext.
I wish they had gone with my recommendation to create a new markup language that used the same syntax to specify the markup elements that it used in applying those elements. (This goes back to the strong Lisp-like idea.) As you’ll see in a moment, SGML lacks this elegance and the specification of just what the markup is has turned into a nightmare of conflicting and increasingly complex notions that makes life hard for us ATPOers. If CALS had not adopted SGML, then it would have died a natural death to be replaced by something better.
Our whole Web and document world is a result of this bad decision.
CALS spawned research into SGML-related hypertext schemes. Much of that hypertext research was conducted by the US intelligence community in projects that may never be detailed, I’m afraid. (I was involved in many of these.) Several hypertext conferences were held, starting in 1987 where some parts of some of these projects were reported. In the next couple years, several proposals were made for a hypertext language either extending or subsetting SGML. One of these took off, the simplest—HTML, Hypertext Markup Language—imagined by Tim Berners-Lee in 1989 and implemented in 1991.
That version took off because it was incredibly simple, an implementation existed, there was a preformed (scientific document) user base, there was the Internet transport vehicle in place (for many years), and the language wasn’t proprietary. Also, so the story goes, Berners-Lee credits an amazingly capable development system for the time in NeXT, the precursor of OS X. HTML looks and acts just like SGML but with a miniscule number of operators and no need for a separate “language” to specify it (because of its simplicity).
Needless to say, as with all cheap and easy solutions, the compromises catch up with you. So in more recent time, the now huge Web community forced a revisiting of SGML to invent another variant in complexity between SGML and HTML. The result was XML, the eXtensible Markup Language, what HTML (and in some respects SGML) should have been from the beginning.
XML has been since 1998 a standard for documents (vastly eclipsing SGML in the user base), database exchange and the reinvented XHMTL (HTML as an XML application). Along with XML are a bewildering array of associated languages, formats, transforms, and such. Adding to the confusion are the hundreds of “standards” (like OPML, RSS, SOAP, and the several application-specific XML formats—Tinderbox, NoteTaker, NoteBook, OmniOutliner, OpenOffice, and now iWork—that employ XML) that we in the ATPO world encounter.
Just as a historical note, in the area of information science, the entire defense and intelligence research community collapsed about a decade ago, and basic research of this kind is now in the hands of others.
About XML
If you are like me and the median ATPO reader, you need a gentle introduction to just what this beast has turned out to be, probably with some hand-holding.
XML “stuff” is found in as many as three places. One place is interspersed within your document as tags, saying for instance that “this bunch of text here is what we call a ‘title’.” If you look in an OPML file from one of our outliners, these are easy to see. It looks just like HMTL tags, which many of us have encountered.
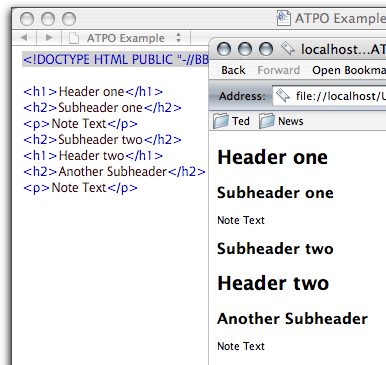
HTML Source
The screenshot shows a rudimentary Web page and the simple HTML that generates it. The tags are those things in angle brackets.
There might be XML-related code in a second area describing in a structured way just what you meant when you said “title” in the document. Often there are complicated rules that designers specify about the relationships among all the elements that are defined: for instance you may specify that a “subsection” must be part of a “section” and there must be at least two subsections in that section for it to exist.
This part is sometimes prepended to the beginning of a document, or more often in a separate file that is used over and over. This can be pretty hairy stuff, and can drive even experts crazy. The official name is DTD, Document Type Definition, by which they mean the definitions of the “types” (the entities in the tags) in the document.
Whether formally specified or not, Tinderbox will have its own version of these definitions, as will NoteTaker, and all the others on the list. The problem of course is translating from one to the other, and what to do when one has some elements the other does not. And that’s the case between any two interesting outliners on the ATPO list.
DTDs are so hairy in fact that many XML users don’t want to even tinker with them. So they’ll use a standard one depending on the domain of application. In the document world, DocBook is a common one that many tools support. Many disciplines have DTDs which you can explore on XML.org.
Most applications that use XML (including OPML originally) don’t bother with a DTD in fact, assuming that the structure is obvious, or explaining it in plain English.
DTDs might be created (if they are done right) using another XML-related standard, the XML Schema language which provides a means for specifying the thing. There are lots of other competing standards in the DTD space which we won’t mention. Suffice it to say that it is complex, contentious, and confusing.
This is a legacy of basing XML on SGML, and using two completely different languages in the specification: one for the tagging and another to define the structure of the tags. You can blame your ATPO exchange frustrations on the Department of Defense if you want. I do.
The third area you might find XML-related stuff is in the actual presentation of the file. This won’t matter so much to ATPO readers. Applications that natively use XML (iWork, OmniOutliner, OpenOffice, and Tinderbox) have their own proprietary means for producing what we see. The other outliners translate into XML for export. But they could have used XSL-FO (Formatting Objects) as a standard way of specifying appearance.
Our problem—the problem of getting your power outliner XML from a mindmapping tool, to an outliner, and on to a page layout program and back, or getting your outliner to dynamically import from your database—is in the DTD side. Fortunately, there is another part of the XML standard that can help us. XSL, the Extensible Stylesheet Language is yet another language (!) whose purpose is to translate XML from one format to another. XSL is a family of specifications using the same language. We already mentioned XSL-FO, but there is a sibling specification called XSLT, XSL Transformations.
Whew, that’s a lot of acronyms. There are lots more where those came from, and all of it is unfriendly.
An ATPO user who wants to tie applications together has a few choices:
- Just use OPML as is. It is a simple specification in XML that just about everybody supports. You don’t have to know what’s in it to use it as an intermediate format among applications of interest.
- Use XML, taking the XML format of one application and translating it to another in an ad hoc manner. Maybe this would be useful if you plan, for example, on spending a year writing a book in OmniOutliner and you want it published in Publicon, so you know the originating and receiving applications.
- Do number (2) but do it in a reusable, wholesale but more expensive way using the XSL Transformations language and perhaps some associated tools.
- Do number (3) but have the work already done for you for each application in the ATPO Transformation specification, but you still might want to tinker with how features from one application translate to another.
Today, we’ll just introduce OPML files.
OPML Files
The good news is that OPML files are easy to look at and understand. The bad news is that they are useless for real outliner integration.
Here is a simple outline in OmniOutliner Pro:
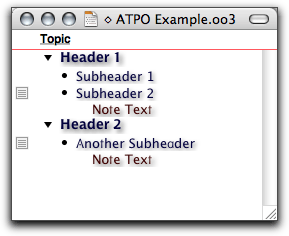
OmniOutliner Example
and here’s what it exports as in OPML format:
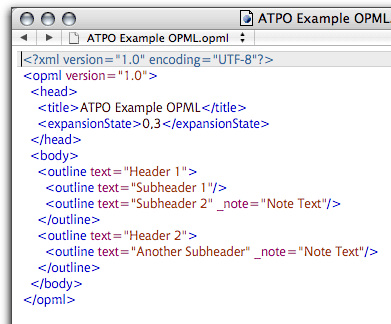
OmniOutliner OPML
It is a bit more complicated than HTML, but most of it is pretty obvious, right? That bit at the top about “expansion state” records which headers were collapsed. In our case, none of the subheaders were collapsed and three were expanded. An OPML file from Frontier would have lots of other stuff in the header section, like owner and date.
But look at this OmniOutliner document, with a column:
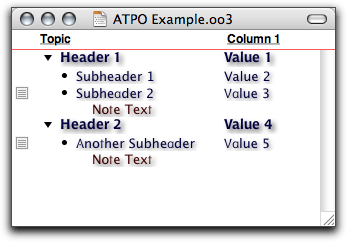
Enhanced OmniOutliner Example
and its associated OPML file:
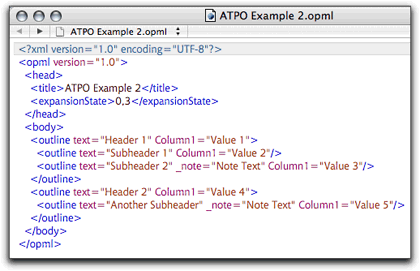
OPML file with Columns
Before, you may have noticed that the outline’s notes weren’t an element (a separate tag). Instead each note was an annotation within an outline element. Here, OmniOutliner has done the same thing with the column. OPML, as it turns out has no definition for a note because Frontier doesn’t do notes. Developers just know what a “note” is when annotated to an OPML outline element (and because OmniOutliner is a leader of sorts).
But “column 1” doesn’t mean anything to a importing application. It wouldn’t know what it is; in fact I could have named that column anything. OmniOutliner only puts it there so that if anyone saves an outline in OPML from OmniOutliner and opens it again in the same application, they can reconstruct the document. That’s because OmniOutliner knows what a “note” is and assumes anything else is a column.
Bad news, right? When this second example is opened in NovaMind for example, it has to import the column values as if they were notes, together with the actual notes.
OPML is best for “flat” outlines where all the information is in headers and there is no separate “notes,” “comments,” or “paragraph” type. This is the case with NoteTaker and Circus Ponies’ NoteBook.
NoteTaker exports “category” and “priority” in the place where OmniOutliner puts column information. OmniOutliner sees those as columns, which of course they are, and displays them correctly when imported. I haven’t taken the time to explore all combinations of OPML-capable outliners, but my impression is that NoteTaker and OmniOutliner are the only ones that handle “column” data.
One approach to a new standard would be for us to specify a standard collection of attributes for the OPML element, essentially expanding the standard. We’d have to have internal links, specific column types with attributes (like priority, start date, owner, cost, and others with data types: numbers, string, graphic, etc.), outlines within notes (Hog Bay does something like this in its OPML), folded state, styles, and clones.
We could fix OPML. Or we could start fresh and do it right, like the CALS folks should have done. In our case, that would mean a new XML specification with accompanying DTD.
If there’s interest in this, we could continue in future columns to explore how to understand and tweak outlining-related XML.
ATPO Tracker
LinkBack
I still use OS 9 (not Classic) for certain things, and whenever I dive into it I’m reminded of things we still don’t have in OS X after all these years. Some of these I’ve mentioned as features of legacy outliners. But another I wistfully yearn for is Publish and Subscribe; that’s where you could create something in one application, say a chart, graphic, or spreadsheet, and “publish” it to the system. Then any other application that supported the technology, say a word processor, could “subscribe” to the element and it would appear as if it were cut-and-pasted.
But this was a live implant. If the element were edited in the original application, the image in the subscribed document would change. Alternatively, double-clicking the element in the subscribed document would open the original application so it could be edited. This last feature was supported in a proprietary fashion in other applications as well, like FrameMaker.
But Publish and Subscribe suffered because of promotion of a much more ambitious technology called OpenDoc that would do this and much more. Although OpenDoc was cosponsored by IBM, it failed to capture mindshare because of Microsoft tactics and was discontinued. But not before some forward-looking small developers bet their companies on it. One of these was Nisus Writer, and when Apple dropped OpenDoc, these early adopters were killed or hobbled.
Now Nisus is bringing back Publish and Subscribe, or so it seems. They’ve announced an open-source project that presumably leverages their OpenDoc experience. One of the partners is OmniOutliner, which will support it in future releases.
This could be big. Right now, Windows has OLE, a comparable technology, and we have zip. It’s really lame to have an outliner that can only make a hyperlink to a file or show what amounts to a “preview” of certain file types. Outliners like DEVONthink can display documents, but only whole documents in an outline of documents. We need LinkBack desperately, in all writing applications, not just outliners.
Especially since we already had it and it was taken away from us.
Presumably, most envisioned uses are in the page-layout and composition areas, for example a document that included spreadsheets, charts, and illustrations from three external applications. Naturally, this will be of importance to ATPO readers who use outliners to create such documents. But I think the influence will be felt most deeply elsewhere in the outlining world.
Tinderbox, as an example, is terrific for organizing notes and their relationships, but its editor for creating notes—doing actual writing—is tepid. LinkBack could fix this.
Outlining is the strongest on-screen interface paradigm at the cheapest cost for working with structure, but that structure (parent-child) has severe limits. Clones are a way of stretching the paradigm. LinkBack could be seen as a way of extending the cloning technique among different outlines, even from different outliners.
A primary use of outliners is an ordered information store. Referencing or linking to content external to the outline is a must. Displaying and editing such content in an outline has been called “transclusion” by innovators and researchers as the ultimate in this regard. LinkBack could give us real transclusion, maybe even with the accompanying notion of “purple numbers.”
Let’s hope it catches on.
FullWrite Pro
Speaking of legacy outliners, that column on legacy outliners seems to have put new life into the communities surrounding a few of them that run well under Classic. Dave Trautman is the FullWrite Pro guru, and he reports that things are going well in that department. He has put up a new information page.
Curio
A growing trend in software is the splitting up of applications into Basic and Pro versions. OmniOutliner, VooDooPad, and DEVONthink are ATPO examples. Now, Curio joins the club. Their new version 2.2 comes in four versions. There are the Pro and Basic versions of course. In between is the Home version.
The Basic edition sells for $39, and has all the features we’ve chosen to mention in prior ATPO columns, minus the Internet search feature they call Sleuth. The Home version at $79 adds Sleuth, some basic tablet support, and export/publishing options. The $129 Pro version adds some Sleuth tailoring, project sharing features, and templates.
The professional edition is available at an educational price of $65, but few people will buy it because at the same price and collection of features you can get the K-12 version. The only difference is in a different collection of Sleuth sites and the templates are educationally oriented. They may be trying to move into the market that has been sustaining Inspiration: secondary education.
I’m glad to see this refocus in target groups. Originally, Curio was targeting the creative professional workflow. This is not a consumer use, and some reviewers were puzzled about just how they’d use this novel thing. (As a point of reference, Creator was one of the coolest Mac-only packages for a dozen years or so before going cross-platform. It was the most scriptable application on the Mac, and supported QuickDraw GX before anyone. GX did things that still amaze me, but like OpenDoc it was discontinued. I used it extensively for consumer-type stuff, but few Mac users could figure out any use for it because it only cared about a narrow professional market: newspaper ads.)
I do not know whether Curio’s move indicates a new focus on the “home” user, but I hope so. And I hope we see more outlining features in their ordered lists.
Current
In keeping with the pro-nonpro idea, Near-Time Flow has broken out a personal version as well. They call this one Current. Flow is targeted at group collaboration, a pretty hairy professional use. That collaboration capability adds quite a few user interface challenges.
Current, on the other hand, eschews the collaboration baggage while keeping the blogging and RSS-collection capabilities. Neither Current nor Flow is an outliner yet, but I’m betting they will be.
Current is free at present, but it looks like the price will be $50.
Tinderbox
Tinderbox is not for everyone, and even among Tinderboxers it is not best for all outlining tasks, but every ATPO reader should check it out. It is serious software made more serious with the update to 2.4.
(Updates in the Tinderbox world are free if you paid in the last year, and $70 if not. That $70 buys you another year.)
This update is significant. Tinderbox has a core attraction of four elements: rich hypertext, Web integration, multiple views including a handy zooming “map” view, and agents. The update enhances the latter three.
Many elements of Tinderbox are hard to get, but exporting to the Web seems the most difficult and least automatic to me. Eastgate works on this by including templates and “assistants.” They’ve improved this.
Where OmniOutliner, for example, explores new ways of exploiting outlining in Aqua, Tinderbox is inventing its own user interface. It’s added some very nice touches in the map view, allowing you to “group” note boxes in an “adornment.” The note’s color, previously associated with the box in the map view, now also pertains to the “header” in the outline view. I really appreciate this.
Also appreciated is the long-awaited appearance of pop-up entries for some attributes. It was absolutely archaic to have a dozen prototypes, but to select one you had to remember its name and type it exactly.
But surely the big addition is “rules.” Tinderbox has fairly smart “agents,” which gather clones of notes with various characteristics and can change just about any attribute. Tinderbox calls the scripts that agents use “actions.” Often to perform an action on a note (like turn the title red if it is a draft that is more than one week old) you’d have to make an agent elsewhere in the outline that did this by collecting clones and changing them. Messy.
Now you can have actions (using the same operators) that apply to notes without doing the clone routine.
Mellel
We now have version 1.9 of Mellel, which adds style sheets to this outlining word processor. I haven’t yet written my column on why styles are important. The short version is: outlining is first about visual structure of information; styles are about visual characteristics of information (in both cases, “information” in text). The two work well together. Mellel’s implementation is refreshingly capable. Unfortunately, it is targeted at what we might call the layout view and does not affect the outline directly. But still, an advance.
StickyBrain
A column on snippet managers is another column to come. StickyBrain will be one of the applications featured; it is coming on strong with its aggressive development. Like many of the task managers we mentioned last month, StickyBrain integrates with AddressBook. Now it has integration with the iPhoto database (something like NovaMind): you can browse your photos in StickyBrain’s interface, which is shared by a scrapbook database. Chronos incidentally sells content for that scrapbook .
NewNOTEPAD Pro
Speaking of text editing, NewNOTEPAD Pro has a minor update. This is a $23, simple Carbon two-pane outliner. Its features are unremarkable, but this update adds the ability to use Emacs keyboard commands. BBEdit and Mailsmith, both from Bare Bones Software, also have this feature. Any discussion having to do with Emacs quickly becomes a religious argument, but a case can be made for it as the most capable text editor. Emacs keyboard commands are decidedly unMac-like, but allowing the choice shows that someone is thinking about power writers.
An ATPM review of an older version of NewNOTEPAD Pro can be found in the July 2001 ATPM.
Circus Ponies NoteBook
NoteBook has been updated to 2.0 with a slew of new features. But you’ll have to wait a month for my report, as it was released too late for an evaluation.
![]() Copyright © 2005 Ted Goranson,
tgoranson@atpm.com. Ted Goranson has been thirty years in the visualization and model abstraction field. He is slowly beginning a new user interface project.
Copyright © 2005 Ted Goranson,
tgoranson@atpm.com. Ted Goranson has been thirty years in the visualization and model abstraction field. He is slowly beginning a new user interface project.
Also in This Series
- A Progress Report · February 2008
- Some Perspectives on the Worldwide Developers Conference · July 2007
- Writing Environments, Plus Two New Outliners · November 2006
- Examining New Business Models · September 2006
- Outlining Interface Futures · July 2006
- Outlining Workflows and ConceptDraw · May 2006
- Dossier and Outliner Web Interaction · March 2006
- Two New Outliners: Mori and iKnow & Manage · February 2006
- Styles Revisited, Video Features, and a Proposal · December 2005
- Complete Archive
Reader Comments (13)
I use outliners (MORE then, TAO now, bow-wow, bow-wow -- I'm sorry I couldn't resist) to dump in lots of throughts, fragment of objects, etc. and then to sort them through and evolve into some sort of presentation or contribution to a team effort ... inevitably to be delivered in PPT.
Could this inquiry that you are suggesting toward a common exchange language -- with an implicit skew toward outliner-to-outliner connectivity -- evolve to include outliner-to-MicrosoftApps. Trying to get my nice, tidy, hierarchically precise TAO outline into PPT for finishing up and sharing, is one painful exercise. Perhaps focusing on the platform(s) of the likely ultimate destination applications (presention, page-layout, storyboard, etc) might focus our thinking.
Needless to say, for both OS X and other non-Apple platforms.
Thanks again for stimulating discussion on these topics.
Cheers,
Mark
Where's your mention of Radio UserLand, a cousin of Frontier who has native document-level support of OPML?
Steve Kirks
http://houseofwarwick.com/
ATPO considers Radio and Frontier the same product. Naturally, both support OPML well because it was invented for them, and consequently limited.
Best, Ted
I really wish these columns came out more frequently. It is just too good.
I am clueless on any computer language. I have never done anything with the terminal, applescripts, HTML, etc. What do I do with XML? When I export an XML doc from Voodoo (with pics) to OmniOutliner, I see a bunch of numbers and letters for the pics. HTML works but not like I would like it to. The only option that works decently well between outlining programs is OPML.
But I agree, we need a new language and here is what I would like: an OPML like language that can talk among outliners but also with a simple word document with the user having the options on how the end doc should look with a new set of options (rules) on how it should be displayed on the other side. Almost similar to publish and subscribe but with a lot of more interaction between two softwares. Audio, pictures and video are also being used in these outlines, I hope these are also included in any sort of communal language.
I am still clueless on how XML is really beneficial for me. This side is still sort of confusing. Is there a translater of this language or a reader? I understand these are very basic questions but I am do not have the background for this kind of stuff.
Thank you again for your insight.
You are definitely writing a best of breed series of articles. Thanks.
You said, "If there's interest in this, ..." I say, "YES!"
I just spent huge chunks of time (read days) trying to move a large set of notes from Tinderbox to OmniOutliner. Despite the fact that Tinderbox can generate just about any HTML, I spent hours and hours in BBEdit working out the incompatible details. There are huge differences in how these programs generate and deal with text markup--the stuff between the quotes in the _note element. When OmniOutliner sees something it can't understand (like an HTML <b></b> tag or a special character) it just quits the import. Repeatedly trying and failing allowed me to isolate the issues, but it was a definite one-time, one file effort. Quotes in the Tinderbox notes were a particular rub since they confused the OPML syntax. Amazing how both Tinderbox and OmniOutliner both support bold text in notes, but moving from one to another requires manual massaging of every instanceof bold text.
If I read your goals correctly, tweaking some DTD or XSL code once could solve these issues for any data I may want to move and give me the means to go back and forth between outliners without loss of meaning (unless one of the outliners just don't handle a specific meaning). I think this is a most worthwhile endeavor and would be willing to contribute my meager talent to it.
For example, you begin to talk about the role of style in outlines. The role presentation plays is important, but are these style characteristics best captured in a manner orthogonal to structure? If style is used in presentation to express structure, perhaps style should annotate structure in-band? I would like to hear your insights on such topics.
Anyway: Anyone knows of any app whatsoever that produces viable OPML in OS 9?
Thanks.
Øystein, Norway
Oh, I was so looking forward to it. Can we clone Ted?
Cheers!
P.S. OML looks good, Will. I will work on that.
Radio runs just fine in OS 9, and does just fine with OPML.
Actually, I'm one of the development team members. Unfortunately, OPML extraction wont be before version 1.5.0.
Add A Comment